

How we talk to AI and automate tasks that we were not able to just a year or two ago? Includes our battle tested methods of prompting and the reasons why to use them over traditional model training.
✍️ Co-written with Adam Horka
The rise of Large Language Models (LLMs) introduced a massive leap in our ability to optimize text-related processes with AI technology.
While just few years back, you often had to train your own AI models to perform a categorization task — which is heavy on time, resources and data quantity/quality required. Recently, we got to a stage, where many problems can just be solved with precise Prompt Engineering.
Prompt Engineering is a recent methodology of giving textual instruction to AI which quickly grew into becoming a relevant specialization or even a job position. It gives us an opportunity to provide relatively complex instructions to the LLM, which understands and executes them.
In other words, we can talk to AI now.
Document categorization: how we do what we do
So far, our project experience at Ableneo led us to the realization that document or email categorization is a very common activity for majority of our clients, often consuming a significant amount of employees’ time.
Moreover, document sorting usually requires a follow-up activity, such as:
- archiving the content,
- responding to it via email,
- creating an opportunity in a CRM,
- or automatically creating a meeting in your calendar.
All of this can be automated as well!
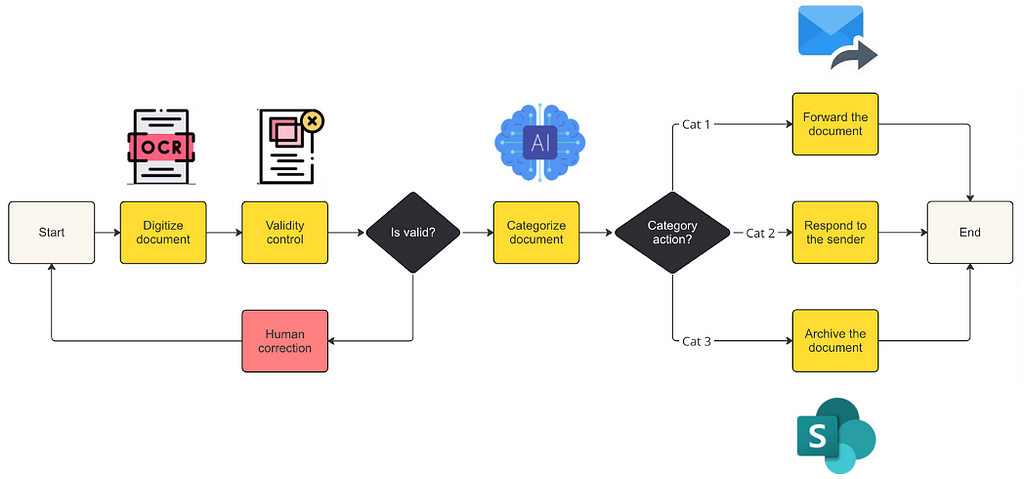
Using a combination of the state-of-the-art OCRs, LLMs and other techniques we are now capable of automating tasks we could not automate just a year or two ago.
A crucial part to the automations we do is instructing the LLM to do the job using advanced prompt engineering techniques, such as zero shot or few shot classification prompts.
The workflow connecting all the components together is usually written in a modern automation tool, like Kognitos, allowing you to combine OCRs, LLMs, Speech recognition techniques, Python modules and various integrations with systems like SAP, Sharepoint, Salesforce and others.
Classification prompts — the details
When it comes to automating document processing tasks using LLMs, one of the most critical aspects is how we tailor our prompts exactly to the needs of our clients.
Prompt containing concise and specific requirements is central to unlocking the full power of LLM — not only for classification, categorization, but also other common tasks.
In our projects, we use the following methods of prompting, depending on the context and complexity of the process that we are automating:
Zero-shot prompting
Zero-shot prompting refers to the ability of an LLM to perform a task without any prior examples.
In this approach, we simply provide the model (such as Chat GPT) a clear instruction about what needs to be done, and it attempts to classify or sort the document based on its extensive pre-trained knowledge.
For instance, if we need to categorize emails into “invoices,” “customer queries,” or “internal communications,” we can design a prompt that asks the model to read the email content and classify it into one of the categories provided in the prompt, even if the model has never performed a similar task before.
Few-shot prompting
Few-shot prompting, on the other hand, involves providing the model with a few examples of the task at hand.
This is particularly useful when the categorization task is more complex either because of the number of the categories, the variety of documents per single category, or the overlap between some of the categories.
In cases like this, the model needs to understand specific contexts or patterns. By showing the model a few instances of these critical categories, we can direct its attention and significantly improve its success rate in categorization.
Iterative Refinement
A good practice is to start with a simple zero-shot prompt providing just the necessary information about the task.
Then, based on the results of the first run, we can identify the problematic categories and add examples and hints for the selected categories to prevent providing the LLM with unnecessary clutter of data, that could lead to confusion of the used model or even to decrease of final accuracy.
This process is also known as the Iterative Refinement.
Why use prompting over traditional model training?
Traditionally, categorizing documents with AI required either building a custom model from scratch or transfer learning an existing model to fit our needs. This process is not only resource and time-consuming, but also data intensive.
Training these models demands a large dataset, manually labeled to cover a significant portion of documents. Additionally, the process requires big computational resources and expertise in machine learning.
Training and running own models is not a viable business model for many small to mid-sized companies or companies without dedicated software & AI engineering teams.
In many cases, it is not even required anymore, since it could be accomplished by using different state-of-the-art models provided by the companies such as OpenAI and a bit of prompt engineering.
To sum it up
The modern approach to document categorization with LLMs, through techniques like zero-shot and few-shot prompting, offers a powerful alternative to the traditional AI model training.
It allows for a faster, more flexible, and cost-effective automation of workflows, enabling organizations to optimize their processes with unprecedented efficiency.
Want to drive meaningful change with AI? Get in touch at ableneo.com and let’s talk about how we can help.
Talking to AI: automating document categorization and workflows was originally published in ableneo Technology on Medium, where people are continuing the conversation by highlighting and responding to this story.